
 Pearson’s linear product-moment correlation coefficient is highly sensitive to outliers, as can be illustrated by the following example. Several alternatives exist, such as Spearman’s rank correlation coefficient and the Kendall’s tau rank correlation coefficient, both contained in the Statistics and Machine Learning Toolbox.
Pearson’s linear product-moment correlation coefficient is highly sensitive to outliers, as can be illustrated by the following example. Several alternatives exist, such as Spearman’s rank correlation coefficient and the Kendall’s tau rank correlation coefficient, both contained in the Statistics and Machine Learning Toolbox.
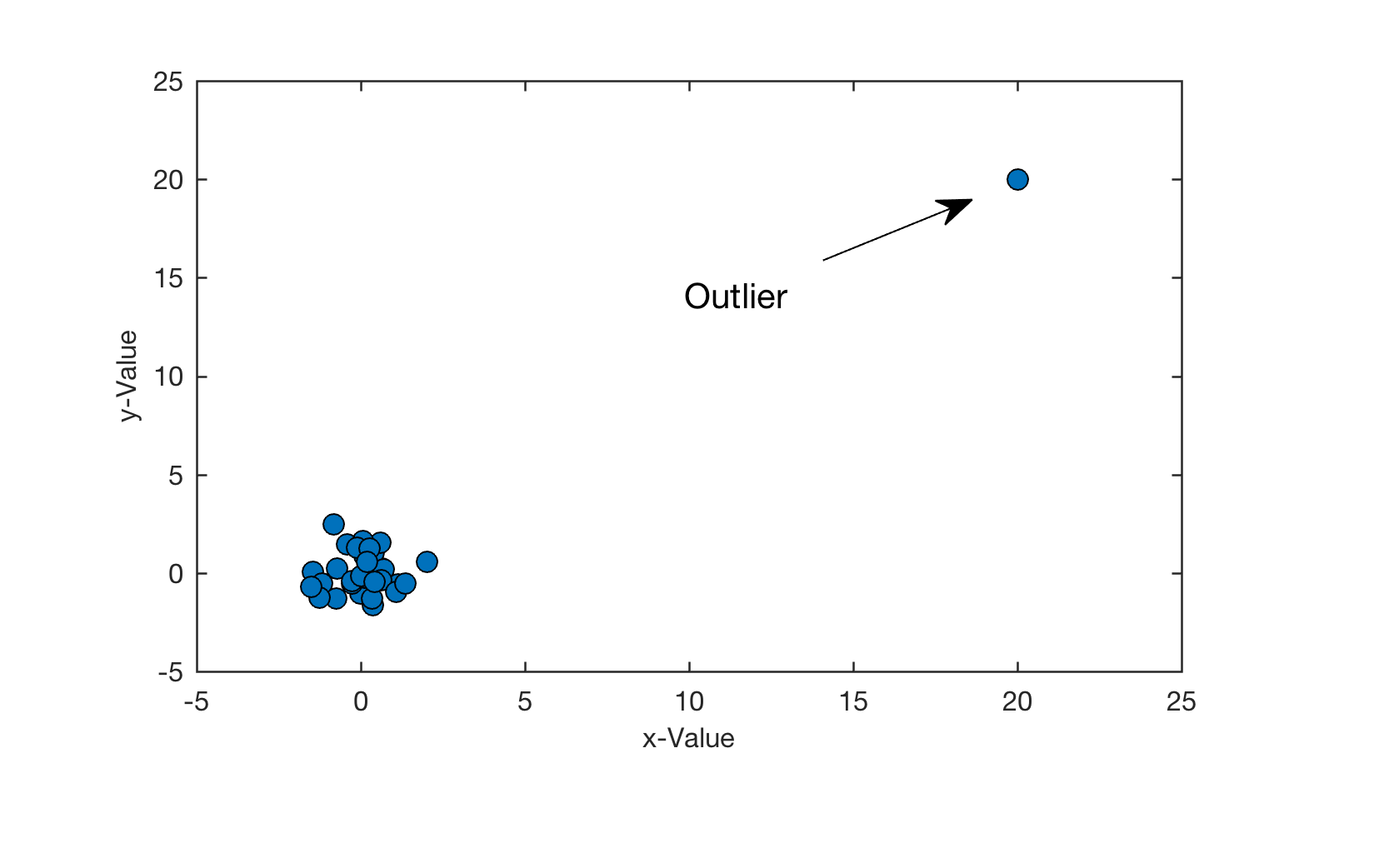
Let us generate a normally-distributed cluster of thirty data with a mean of zero and a standard deviation of one. To obtain identical data values, we reset the random number generator by using the integer 10 as seed.
rng(10) x = randn(30,1); y = randn(30,1); r_pearson = corr(x,y,'Type','Pearson')
which yields in a value close to zero (r_pearson = 0.0302) since the random data are not correlated. Now we introduce a single outlier to the data set in the form of an exceptionally high (x,y) value, in which x=y. The correlation coefficient for the bivariate data set including the outlier (x,y)=(20,20) is much higher than before (r_pearson = 0.9403).
x(31,1) = 20; y(31,1) = 20; r_pearson = corr(x,y,'Type','Pearson')
We can create a nice plot of the data set by typing
figure1 = figure(...
'Position',[100 400 400 250],...
'Color',[1 1 1]);
axes(...
'Box','on',...
'XLim',[-5 25],...
'YLim',[-5 25],...
'Units','Centimeters',...
'Position',[2 2 10 6],...
'LineWidth',0.6,...
'FontName','Helvetica',...
'FontSize',8);
hold on
line(x,y,...
'Marker','o',...
'MarkerFaceColor',[0 0.445 0.738],...
'MarkerEdgeColor',[0 0 0],...
'LineStyle','none'),
xlabel(...
'x-Value',...
'FontName','Helvetica',...
'FontSize',8);
ylabel(...
'y-Value',...
'FontName','Helvetica',...
'FontSize',8);
annotation(figure1,'arrow',...
[0.5925 0.7],...
[0.7 0.77]);
annotation(figure1,'textbox',...
[0.48 0.645 0.1 0.05],...
'String','Outlier',...
'LineStyle','none',...
'FitBoxToText','off');
Several alternatives exist to Pearson’s correlation coefficient, such as Spearman’s rank correlation coefficient proposed by the English psychologist Charles Spearman (1863–1945). Spearman’s coefficient can be used to measure statistical dependence between two variables without requiring a normality assumption for the underlying population, i.e., it is a non-parametric measure of correlation (Spearman 1904, 1910).
Another alternative to Pearson’s correlation coefficient is the Kendall’s tau rank correlation coefficient proposed by the British statistician Maurice Kendall (1907–1983). This is also a non-parametric measure of correlation, similar to the Spearman’s rank correlation coefficient (Kendall 1938).
Both correlation coefficients are included in the function corr of the Statistics and Machine Learning Toolbox of The MathWorks (2016):
r_pearson = corr(x,y,'Type','Pearson') r_spearman = corr(x,y,'Type','Spearman') r_kendall = corr(x,y,'Type','Kendall')
which yields r_pearson = 0.9403, r_spearman = 0.1343 and r_kendall = 0.0753 and observe that the alternative measures of correlation result in reasonable values, in contrast to the absurd value for Pearson’s correlation coefficient that mistakenly suggests a strong interdependency between the variables. More about these correlation coefficients and the use of bootstrapping to detect outliers is included in the MRES book.
References
Kendall M (1938) A New Measure of Rank Correlation. Biometrika 30:81–89
MathWorks (2016) Statistics Toolbox – User’s Guide. The MathWorks, Inc., Natick, MA
Pearson K (1895) Notes on regression and inheritance in the case of two parents. Proceedings of the Royal Society of London 58:240–242
Spearman C (1904) The proof and measurement of association between two things. American Journal of Psychology 15:72–101
Spearman C (1910) Correlation calculated from faulty data. British Journal of Psychology 3:271–295